Сергей Нечитайло
Музыкальное Оборудование
ноябрь 2004
Сравнение двух программ синтеза вокала.
Задачи, стоящие перед синтезаторами с момента их возникновения и по нынешний день, можно условно разделить на две основные категории. Это, во-первых, создание абсолютно новых звуков, эффектов и инструментов, а, во-вторых, — моделирование уже существующих. Совершенствование и расширение ассортимента методов синтеза позволило за относительно короткий срок добиться просто феноменальных результатов. Происходившие параллельно микроминиатюризация элементной базы электронных устройств, расширение использования цифровых технологий и, наконец, стремительное развитие компьютерной техники обеспечили условия для комбинирования разных способов звукообразования, более гибкого управления, существенного увеличения количества составных модулей, а главное, — общего кардинального повышения мощности синтезаторов.
Специализируясь на программных синтезаторах и постоянно отслеживая все более или менее значимые продукты на рынке современных музыкальных технологий, я уже давно перестал удивляться появлению различного рода новинок, каждый раз получающих сенсационные титулы «революции в моделировании», «прорыва в мире синтеза» и т. д., и т. п. Все эти виртуальные реинкарнации старых аналоговых инструментов, новомодные физмодели, навороченное компьютерное управление звукообразованием и исполнением я рассматриваю, скорее, как естественный результат современного технического прогресса. Даже программное воплощение уже не инструментов, а музыкантов, на них играющих (Virtual Guitarist, Groove Agent), или аранжировщиков (Band In Box, Onyx) я воспринял спокойно, хотя четко осознавал их отличие от обычных синтезаторов.
Однако возможность моделирования вокала и, тем более, — вокалиста, почему-то всегда казалась мне чем-то из разряда научной фантастики. То есть, понятно — рано или поздно это обязательно будет сделано, но… когда-нибудь позже. И вот в прошлом году мне на глаза попадается анонс программы Yamaha Vocaloid. Слушая демонстрации (еще на японском языке), я постоянно ловил себя на мысли, что это какой-то хитрый обман. Только вот удивляться-то было совершенно нечему — в операционных системах давным-давно имеется штатный компонент синтезатора речи (зайдите в Панель управления своего PC и кликните по пиктограмме Речь). Осталось лишь научить синтезатор петь…
Голосовой аппарат человека
Сначала давайте вкратце разберемся с физикой голосового синтеза и историей его развития. Прежде всего, посмотрим, как устроен голосовой аппарат человека — надо же хоть в общих чертах представлять себе предмет моделирования.
Человеческий голосовой (или речевой) аппарат представляет собой совокупность нескольких органов. Во-первых, это дыхательные органы (легкие, бронхи, трахея, диафрагма, межреберные мышцы), работа которых создает воздушный поток — движущую силу любой речи или пения. В зависимости от фазы дыхания (вдоха или выдоха) поток движется по дыхательным путям в двух противоположных направлениях. Фактически все процессы звукообразования при пении или во время разговора осуществляются на выдохе. Стоит отметить, что встречаются случаи (некоторые языки, особые техники вокала, фольклор и т. п.), когда звуки извлекаются и на фазе вдоха, но поскольку это скорее редкое исключение, чем правило, в рамках данной статьи я к ним больше возвращаться не буду.
Во-вторых, это пассивные голосовые органы: зубы, альвеолы, твердое небо, носовая полость, глотка и гортань. Они являются неподвижными и служат точкой опоры для активных органов.
В-третьих, это активные голосовые органы, которые подвижны и производят основную работу артикуляции: язык, губы, мягкое небо, маленький язычок, надгортанник и голосовые связки.
И, наконец, в-четвертых, это мозг — «центральный процессор» человеческого организма, который отвечает за управление и координацию дыхательных и активных голосовых органов (естественно, помимо всего прочего).
На пальцах, работу голосового механизма (то есть процессы звуко- и словообразования) для более удобного восприятия можно схематично представить следующим образом. Выработка «основного сигнала» голоса, который имеет свои тембровые особенности и может варьироваться по громкости и частоте, осуществляется органами дыхания и голосовыми связками. Различные способы модуляции этого «несущего» сигнала, то есть придание «чистому» голосу способности передавать речевую информацию, производятся пассивными и активными голосовыми органами. Оба процесса должны действовать в жесткой взаимосвязи друг с другом, что и происходит при помощи синхронного управления ими из одной «высшей» инстанции — мозга. Вам не кажется, что эта схема очень напоминает конструкцию синтезатора или радиопередатчика? Налицо блок генератора «несущей» (или аддитивно-субтрактивная часть синтезатора), блок модуляции и т. п.? Неужели, человеческая речь является настолько сложной субстанцией, чтобы ее нельзя было с тем или иным успехом смоделировать? Оказывается, это вполне возможно. Давайте сперва посмотрим, что она собой представляет «под микроскопом».
Речь
С физической точки зрения речь человека представляет собой определенную последовательность звуков разного типа, которые могут быть тональной, шумовой или смешанной структуры. Если произносятся тональные или смешанные звуки (гласные, носовые, звонкие согласные, они еще называются voiced — вокализованными), голосовые связки вырабатывают периодические колебания выходящей из легких воздушной струи той или иной частоты. Эти колебания воздушного потока возбуждают полости голосового тракта, которые являются природными резонаторами. Во время разговора геометрические размеры и форма этих полостей меняется, что приводит к изменению и их резонансных частот, или формантных частот. Если же произносятся звуки шумового характера (их еще называют глухими, или devoiced — невокализованными), голосовые складки «выключаются» из процесса звукообразования. Проходя через суженные ротовую и носовую полости, воздух создает турбулентные завихрения и порождает непериодические шумоподобные колебания. Еще одна группа звуков образуется «взрывным» способом, когда речевой тракт резко открывается после предварительного усиления давления воздуха в ротовой полости. Они могут быть как глухими, так и звонкими, — в зависимости от участия в звукообразовании голосовых связок.
Последовательности гласных и согласных, звонких и глухих, свистящих, шипящих и остальных звуков речи произносятся слитно с разделительными паузами, разграничивающими отдельные слова или иногда даже слоги. Эта слитность произношения обуславливает взаимное влияние соседних звуков друг на друга. Таким образом, в различных сочетаниях одни и те же звуки речи могут звучать по-разному. Поэтому современная лингвистика рассматривает полный набор звуков конкретного языка не как сумму типовых гласных и согласных (как правило, соответствующих буквам алфавита), из которых строятся слова, а как общее количество всех участвующих в произношении неповторимых звуков. Казалось бы, таких звуков должно быть бесчисленное множество — ведь, во-первых, разным людям присущи и разные размеры органов речи, а, во-вторых, индивидуальная манера произношения так же уникальна, как, например, отпечатки пальцев или рисунок сетчатки глаза. Тем не менее, при всех упомянутых различиях носители конкретного языка оперируют довольно небольшим количеством звуков. Такие звуки называются фонемами, и их несколько больше, чем букв в алфавите. Например, английский язык содержит сорок одну неповторимую фонему при двадцати шести буквах алфавита. Однако фонемы фонемами, но простым построением цепочек из них не обойдешься — оказывается, одни и те же фонемы в разных сочетаниях имеют различное звучание. Плюс ударение в слове — ударные и безударные гласные даже в одинаковых сочетаниях с соседними фонемами звучат неодинаково. Поэтому кирпичиками, из которых строится речь, современные лингвисты считают не только разные варианты произношения фонем — аллофоны, но и созвучия из двух фонем (дифоны) и даже трех (трифоны).
Ко всему этому следует добавить и такой важный фактор речи, как интонацию — без правильного интонирования даже самые ювелирные построения фонем будут иметь механическое звучание. Человеческая речь очень богата на интонации — не то что отдельные слова, а целые предложения могут кардинально менять смысл сказанной информации только при помощи разного интонирования. Если же мы немного вернемся к теме статьи (посмотрим на речь с точки зрения вокального искусства), то увидим, что при изменившейся роли интонации (она используется главным образом для мелодического интонирования) добавляется большое количество дополнительных средств выразительности: экспрессия, вибрация, более широкое динамическое «дыхание». И все это надо держать в голове, решая проблему синтеза, так как и вокал, и простая речь воспринимаются и оцениваются человеческим ухом гораздо тоньше, чем большинство музыкальных инструментов. Малейший артефакт в звучании имитируемого голоса может загубить даже очень совершенную модель синтезатора, в то время как гораздо большие огрехи в моделировании различных музыкальных инструментов проходят мимо наших ушей фактически незамеченными.
Немного истории
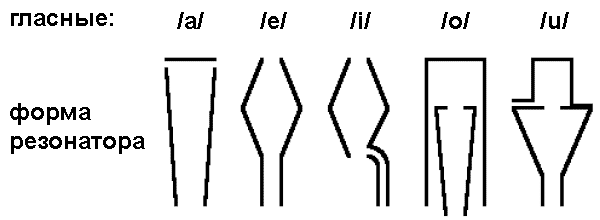
 Первые попытки создать говорящую машину начались во второй половине XVIII столетия — то есть задолго до появления не только компьютеров и синтезаторов, но даже использования человечеством электричества. Возможность создания такой машины в 1761 году высказывал еще великий Леонард Эйлер (Leonard Euler) в своих знаменитых «Письмах к немецкой принцессе». В 1773 году в Копенгагене известный ученый Христиан Готлиб Кратценштейн (Christian Gottlieb Kratzenstein — физик, медик, механик; между прочим, почетный иностранный член Российской Академии Наук, рис. 1) занимался любопытными экспериментами — при помощи акустических резонаторов разной формы (рис. 2), соединенных с трубами органа, он добился узнаваемого воспроизведения различных гласных звуков.
Первые попытки создать говорящую машину начались во второй половине XVIII столетия — то есть задолго до появления не только компьютеров и синтезаторов, но даже использования человечеством электричества. Возможность создания такой машины в 1761 году высказывал еще великий Леонард Эйлер (Leonard Euler) в своих знаменитых «Письмах к немецкой принцессе». В 1773 году в Копенгагене известный ученый Христиан Готлиб Кратценштейн (Christian Gottlieb Kratzenstein — физик, медик, механик; между прочим, почетный иностранный член Российской Академии Наук, рис. 1) занимался любопытными экспериментами — при помощи акустических резонаторов разной формы (рис. 2), соединенных с трубами органа, он добился узнаваемого воспроизведения различных гласных звуков.

В это же время известный венгерский инженер и изобретатель Вольфганг фон Кемпелен (вошедший в историю не только как создатель первого в мире речевого синтезатора, но и как конструктор Шеннбруннских фонтанов, пишущей машинки для слепых, автоматического шахматиста, а также многого другого, рис. 3), начал собственные опыты, которые подвигли его на изобретение и постройку рабочего образца механического оратора. Детальное описание и схемы-иллюстрации машины были опубликованы в его книге «Механизм человеческой речи и описание говорящей машины» (Mechanismus der menschlichen Sprache nebst Beschreibung einer sprechenden Maschine), вышедшей в свет в 1791 году. Устройство фон Кемпелена позволяло воспроизводить не просто отдельные звуки речи, но целые слова и даже короткие предложения. По утверждению изобретателя, за три недели можно было научиться довольно свободно управлять машиной, особенно если «говорить» при ее помощи на латинском, французском или итальянском языке, в то время как немецкий был более сложен для освоения из-за его многочисленных закрытых слогов и последовательностей из согласных звуков.
Машина фон Кемпелена представляла собой механическую модель человеческого голосового аппарата. Роль дыхательной системы исполняли мехи, в качестве голосовых связок использовались проскакивающие язычки из слоновой кости (ну, как в язычковых музыкальных инструментах), ротовая полость и носовые ходы имитировались специальными камерами, сделанными из каучука. Струя воздуха из мехов поступала в «ротовую полость» не только через язычковый «генератор» частоты, но также и по отдельному каналу, что позволяло увеличивать давление в камере при плотном закрытии «рта» для получения взрывных фонем. Плюс к этому машина имела небольшие мехи (приводимые в действие пружиной), которые производили дополнительный выброс потока воздуха. Участие в звукообразовании «носовой составляющей» регулировалось открытием или закрытием деревянных «ноздрей». Управление машиной осуществлялось при помощи обеих рук оператора — предплечьем правой руки качали мехи, а пальцами воздействовали на три рычага, отвечавшие за отдельные фонемы, и управляли «ноздрями», в то время как левой рукой управляли параметрами резонанса «рта», открывая и закрывая его.
Стоит заметить, что из-за несовершенства отдельных узлов конструкции (например, форма «рта» оставалась всегда неизменной, были и другие огрехи), машина, вполне удобоваримо выговаривая отдельные фонемы, весьма фальшиво воспроизводила другие. Хуже всего дело обстояло с согласными «д», «т», «г», «к», а некоторое подобие «л» оператор мог получить, лишь засунув большой палец в каучуковый «рот». Кроме того, в первоначальной конструкции говорящей машины изобретатель не предусмотрел возможность изменения длины звукообразующих язычков в процессе работы (то есть, произвольного изменения высоты голоса), в связи с чем она говорила очень монотонно, безо всякого намека на интонацию. В более поздней версии аппарата фон Кемпелен добавил эту функцию, что здорово оживило речь говорящей машины.
Окончательный вариант машины фон Кемпелена пережил свое время и находится сейчас в стенах одного из крупнейших музеев Европы — мюнхенского Немецкого Музея (Deutsches Museum). Механизм устройства действует до сих пор — работа машины напоминает речь ребенка или очень громко говорящего взрослого. На рис. 4 показан общий вид говорящей машины фон Кемпелена, рис. 5 демонстрирует ее внутреннее устройство.


В XIX веке было сконструировано немало говорящих машин. Однако все они с большим или меньшим успехом использовали те же принципы, что и аппарат фон Кемпелена, — механическое моделирование человеческих органов речи, и я не вижу смысла останавливаться на них в рамках данной статьи. Конечно, читатели, знакомые с историей развития речевых (и не только) синтезаторов, вспомнят и реконструкцию машины фон Кемпелена известным физиком Чарльзом Уитстоуном (Charles Wheatstone), показанную последним в 1835 году в Дублине и обладавшую более внятным произношением, чем ее прототип (рис. 6 — видно воздействие левой руки оператора на каучуковый «рот»). Вспомнят они и юношеские эксперименты будущего изобретателя телефона Александра Белла, который, увидев в 1861 году в Лондоне работу машины Уитстоуна, настолько загорелся этой идеей, что по возвращении в США вместе со старшим братом построил свой вариант говорящей машины, впрочем, не отличавшийся принципиально от реконструкции Уитстоуна.
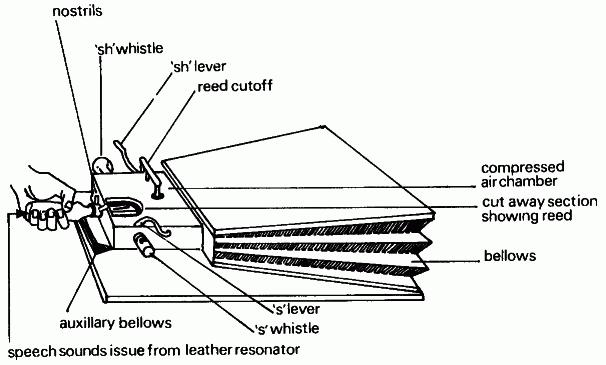
Отдельного разговора заслуживает, пожалуй, только устройство, сконструированное немецким изобретателем Йозефом Фабером (Joseph Faber) в 1835 году (рис. 7), вдохновившемся вышеупомянутой книгой фон Кемпелена. Машина была названа изобретателем «Euphonia» и имела несколько новых интересных технических решений — в частности, в ней моделировались язык и полость глотки, форма которой управлялась оператором. Но самым интересным (с точки зрения темы статьи) было то, что Euphonia умела не только разговаривать (как в полный голос, так и шепотом), но и… петь. Во время демонстрации говорящей машины в Лондоне в 1846 году Euphonia ухитрилась спеть национальный британский гимн «God Save The Queen». Таким образом, она оказалась, видимо, первым в мире искусственным певцом.

Управление машиной получилось более рациональным, так как привод действия механических легких (мехов) был вынесен на ножную педаль. Все остальные команды — изменение высоты тона, параметры артикуляции и т. п. — отдавались со специальной клавиатуры (рис. 8). К сожалению, автору так и не удалось «раскрутить» свое поистине замечательное изобретение (не помогли даже демонстрации машины в Америке), и история с Euphonia завершилась на совсем грустной ноте — в 50-х годах Фабер уничтожил свое детище, после чего покончил жизнь самоубийством.

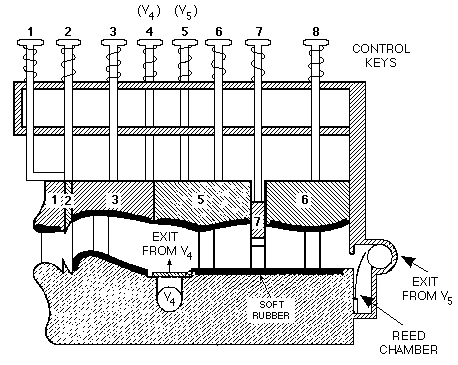
Попытки создания механических моделей речевого аппарата продолжались и дальше, например, уже в XX веке в 1937 ученый из США Риш (R.R. Riesz) придумал гораздо более совершенную конструкцию (рис. 9 и рис. 10). Как видите, это дальнейшее развитие все той же идеи фон Кемпелена, только гораздо более совершенное — при помощи десяти клавиш (напоминающих кнопки-клапаны трубы) оператор двумя руками мог управлять фактически всеми движущимися частями человеческого голосового тракта. По отзывам очевидцев, машина (даже внешне напоминающая музыкальный инструмент) говорила весьма разборчиво — в качестве примера высокого уровня артикуляции приводили очень отчетливо произнесенное слово «cigarette».
Способы физического моделирования речевого аппарата человека существуют и по сей день. Изменились только средства достижения результата — теперь изобретателю не требуется изготовлять сложные конструкции из металла или каучука, так как современный уровень развития науки и вычислительной техники позволяют ему создавать математические модели любой сложности, которые обретают жизнь в виртуальном мире компьютеров.
Однако моделирование голосового тракта человека (неважно, какое оно, компьютерное или механическое) — это лишь один из подходов к решению задачи. Тем более, в XX веке — эпохе широкого использования человеком электричества и бурного развития радиоэлектроники.
Первое в мире полностью электрическое устройство для синтеза голоса было создано Джеймсом Стюартом (James Stewart) в 1922 году. Синтезатор имел зуммер в качестве исходного сигнала и два резонансных контура, моделирующих акустические резонансы голосового тракта. Аппарат мог издавать отдельные гласные звуки с двумя нижними формантами, но не умел имитировать ни согласных фонем, ни связных слов.
Знатоки истории вспомнят и синтезатор Вагнера (Wagner) с четырьмя параллельно включенными резонаторами, и «открытие» японскими исследователями Obata и Teshima в 1932 году третьей форманты для гласных фонем. Однако первым полнофункциональным речевым синтезатором вошел в историю VODER Хомера Дадли. Впрочем, я немного забегаю вперед.
Важнейшей вехой в истории синтеза речи стало изобретение в 1928 году ученым-физиком Хомером Дадли (Homer W. Dudley — рис. 11) из компании Bell Laboratories устройства под названием вокодер (Vocoder). Предназначением вокодера являлось повышение пропускной способности каналов передачи речевой информации — линий телефонной связи. Исходная речь подвергалась анализу, далее данные этого анализа передавались, и на их основе речь заново синтезировалась уже на приемной станции. Чтобы это понять, постарайтесь представить голос в виде несущего сигнала определенной частоты, который во время разговора при помощи органов речи подвергается разным видам модуляций. Снятая анализатором характеристика этих модуляций была значительно меньше по объему, нежели обычная, некодированная речь. Вокодер Хомера Дадли был полосовой, то есть при анализе исходный сигнал разбивался по спектру на несколько частотных полос, в каждой из которых отслеживалось изменение амплитуды. Общая картина изменений амплитуды во всех полосах весьма точно описывала модуляционные воздействия речевого аппарата на голос. Таким образом, по линии связи передается не широкий по спектру сигнал некодированной речи, а лишь данные изменения амплитуды в полосах частот анализатора. Блоку восстановления (синтезатору) оставалось лишь повторить изменения амплитуды в тех же полосах частот — и на выходе прибора воссоздавалась исходная речь. Использование вокодера позволяло уменьшить необходимую ширину полосы пропускания частот, занимаемую каналом связи, до 250-350 Гц (по сравнению с тремя килогерцами без него), позволяя увеличить пропускную способность телефонной линии на целый порядок. Причем коэффициент слоговой артикуляции (то есть разборчивость речи) уменьшался на какие-то единицы процентов (83-85% с использованием вокодера против 90-91% обычной линии).

Конечно, полосовой вокодер еще не верх совершенства, но прогресс не стоит на месте, и со временем появились вокодеры, анализирующие и воссоздающие исходный сигнал другими способами — формантные вокодеры, гармонические вокодеры, гомоморфные вокодеры, вокодеры с линейным предсказанием сигнала и т. д. В рамках данной статьи я не буду останавливаться на подробном описании принципа их действия, равно как и на широком использовании вокодера в современной музыке как самостоятельного эффекта.
Надеюсь, вы понимаете ценность изобретения вокодера в контексте задачи синтеза речи? Говоря проще, самый первый вокодер Хомера Дадли уже позволял полностью воссоздавать речь с качеством, не сильно отличающимся в худшую сторону от передачи той же речи по телефону. Конечно, это еще далеко не все, так как синтезатор приемной станции непрерывно получал сигналы управления — характеристику артикуляции исходного голоса, и ему не приходилось заново воссоздавать произношение и строить слова, как, например, операторам машин фон Кемпелена или Фабера. Зато вокодер представлял собой новую и очень перспективную технологию голосового синтеза, которая с самого своего возникновения показала отличный результат. Говоря фигурально, искусственный собеседник получил вполне качественный (по меркам своего времени) речевой аппарат, и можно было переходить к более высокоуровневым задачам — учить его говорить самостоятельно.
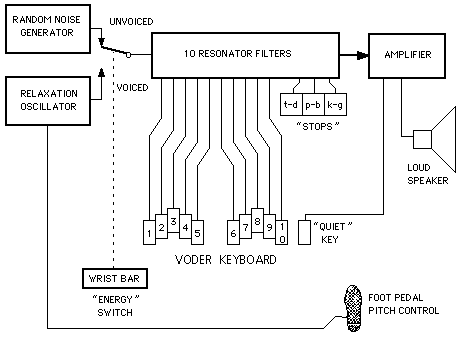
В 1939 году на Всемирной Выставке в Нью-Йорке и Сан-Франциско компания Bell Laboratories представила на суд общественности созданный Хомером Дадли в 1936 году полнофункциональный голосовой синтезатор под названием VODER — сокращение от Voice Operating Demonstrator (рис. 12).

В основе синтезатора лежал принцип воссоздания речи вокодера. Как и механические говорящие машины, VODER управлялся оператором и служил, скорее, демонстрацией возможностей данного типа речевого синтеза (как это, впрочем, и следует из его названия), нежели устройством, готовым к широкому использованию. Конструктивно VODER имел переключатель типа исходного сигнала (тональный или шумовой) и педаль управления основной частотой. Исходный сигнал пропускался через десять полосовых фильтров, уровни выхода которых управлялись пальцами при помощи клавиш. Три дополнительные клавиши отвечали за имитацию взрывных согласных. Окончательный сигнал поступал на усилитель мощности и выводился через динамик (рис. 13). Требовался недюжинный навык со стороны оператора, чтобы «сыграть» на синтезаторе слово или фразу (любопытно, что в 1961 году девушка-оператор даже по прошествии двадцати лет после описанных событий сумела успешно привести синтезатор в действие). Нельзя сказать, что VODER обеспечивал прямо-таки идеальное качество синтезируемой речи, но возможности новой технологии демонстрировались им отлично, а главное, он подвиг многих ученых на дальнейшие изыскания в области речевого синтеза. Надо сказать, что и многие современные речевые синтезаторы имеют архитектуру, сходную с VODER.
Совершенно иной принцип синтеза речи был разработан в конце сороковых годов прошлого века в стенах частного научно-исследовательского института Haskins Laboratories группой ученых под руководством Франклина Купера (Franklin S. Cooper, рис. 14).

Способ получил название Pattern Playback (буквально — «воспроизведение образца»). В 1950 году было завершено создание самого синтезатора, который служил главным образом для исследований распознавания и восприятия речи и представлял собой как бы звуковой спектрограф навыворот. Конструкция аппарата была следующая (рис. 15).
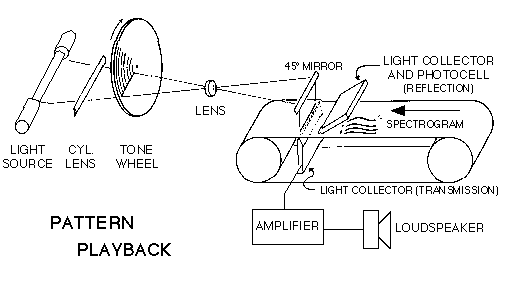
Луч света направляется на вращающийся диск, который является ни чем иным, как куском фотопленки с проявленными на нем пятьюдесятью концентрическими полосками — оптическим представлением звуковых колебаний разных частот (аналогичным способом на киноленту записывается звуковое сопровождение). Частоты дорожек были подобраны таким образом, что представляли собой базовую частоту и 49 ее гармоник. При рабочей скорости вращения диска (1800 оборотов в минуту) основная частота равнялась 120 герцам, а частота последней гармоники — 6 килогерцам. Пропущенный через крутящийся «тональный диск» (tone wheel) луч света, отражаясь от зеркала, проходит через пленку со спектрограммой и попадает на фотогальванический элемент и дальнейшую электронную схему (усилитель, динамик), преобразующую световое давление каждой дорожки в звуковые колебания соответствующих частот. Картинка спектрограммы на пленке, пропуская или отражая поток света дорожек, определяет уровни громкости каждой из гармоник. Поскольку пленка перед фотоэлементом находится в движении, можно динамически изменять частотный состав синтезируемого звука, «подсовывая» под луч разные картинки спектрограмм, то есть шаблоны, паттерны. Если на пленку последовательно поместить спектральные снимки человеческой речи — аппарат заговорит, хотя и монотонно (без интонаций), так как из-за фиксированной скорости вращения тонального диска частота голоса будет неизменной. Само собой, кроме реально снятых спектрограмм речи можно было проигрывать и картинки, нарисованные от руки. На рис. 16 показано спектрографическое изображение на ленте синтезатора фразы «Four hours of steady work faced us». Обратите внимание на участки ленты, заштрихованные точками, — таким образом осуществлялась запись шумовых составляющих речевого сигнала.
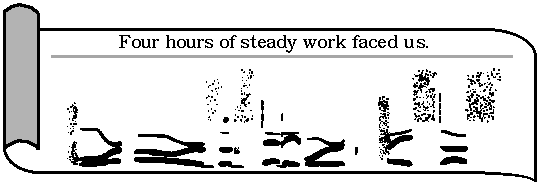
Звучал синтезатор Pattern Playback очень разборчиво, хотя речь больше напоминала голос робота, нежели человека. На рис. 17 показано само устройство.

Хотя идея Pattern Playback была оригинальна и перспективна, все же синтезатор являлся в какой-то степени уникальным, так как в связи с развитием радиотехники большее распространение получили целиком электронные системы синтеза речи. В большинстве таких систем, которые были разработаны и сконструированы, начиная с 50-х годов XX века, обычно прослеживалось общее направление — исходный электрический сигнал обрабатывался частотным фильтром. Исходный сигнал был либо тональным для вокализованных звуков речи, либо непериодическим (шумовым) для невокализованных составляющих. Фильтр использовался для имитации резонансных свойств голосового тракта. В те времена существовали два принципиально различающихся подхода к решению этой задачи. В первом из них для моделирования артикуляции использовались целые каскады из огромного количества электрических цепей, каждая из которых отвечала буквально за отдельный миллиметр голосового тракта. Другой способ был проще — относительно небольшое количество резонансных контуров моделировало уже готовые форманты, то есть резонансы голосового тракта, независимо от его формы.
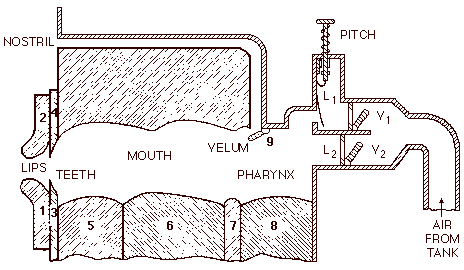
Практически одновременно в 1953 году появились два первых динамически управляемых формантных синтезатора — PAT Вальтера Лоуренса (Walter Lawrence) и OVE Гуннара Фанта (Gunnar Fant). PAT (Parametric Artificial Talker) конструктивно состоял из трех электронных формантных резонаторов, включенных параллельно. Входной сигнал мог быть либо шумовым, либо тональным (гудение зуммера). При помощи специальных шаблонов осуществлялось управление параметрами резонаторов, основной голосовой частоты, уровнями тонального и шумового сигналов. OVE (Orator Verbis Electris — на рис. 18 синтезатор показан вместе с его изобретателем) использовал другую архитектуру. Его формантные резонаторы соединялись последовательно, причем два из них, отвечавшие за самые нижние форманты, управлялись по частоте. Также регулировались параметры «голоса» — его частота, амплитуда и т. п. Первоначальный OVE был предназначен для синтеза только гласных звуков. Дальнейшие модификации добавили ему управление амплитудой формант и отдельный контур для фрикативных звуков (тип согласных, например, «f», «t», «s», «h»). Впоследствии синтезатор был переконструирован по каскадной схеме. Новый OVE — OVE II стал использовать отдельные блоки, моделирующие работу голосового тракта для гласных звуков и согласных фонем разного типа (носовых, фрикативных, т. п.). В качестве голоса использовались тональные звуки и разные типы шумов. Потом были созданы еще более совершенные модели: OVE III и GLOVE, а в конечном итоге развитие принципов проекта OVE легло в основу коммерческой «говорящей» системы Infovox, существующей в настоящее время.

К сожалению, в одну статью при всем желании даже вкратце не впихнешь информацию, которой хватит на добрую пару томов. Я мог бы рассказать и о первом артикуляционном синтезаторе DAVO, и о формантном синтезаторе POVO, и о системах с линейным предсказанием, и о многом другом, но, боюсь, и так уже перешел все мыслимые границы. Поэтому, заканчивая повествование об истории синтеза речи, скажу, что после 1970-х годов дальнейшие разработки в этой области велись в основном с использованием компьютерной техники. Ее развитие позволило моделировать сами устройства (физические, акустические, электронные), с помощью которых раньше моделировалась речь. Компьютеры позволили, наконец, применить наработанные за много лет технологии для практического использования и создать системы, преобразующие написанный текст в звучащую речь. Такие системы получили название Text-to-Speech Systems (TTS). Ранее я уже писал, насколько тонким процессом является соединение звуков речи в разборчивые слова. Однако прежде надо решить еще одну нелегкую задачу — преобразовать текст в последовательность фонем. Человеку, которого учили читать с детских лет, на первый взгляд эта задача кажется простой. Но попробуй научи читать машину! Ведь сам текст несет крайне мало информации о произношении написанного. Кроме того, в тексте постоянно встречаются различные аббревиатуры, сокращения и прочие элементы, распознаваемые человеком не только по устоявшимся правилам, но порой и по контексту изложения. Существуют два типовых подхода к решению задачи. Первый из них предлагает создать исчерпывающий словарь произношений, а второй — научить машину правилам чтения. Создать абсолютный словарь — задача чисто физически невозможная. Не говоря уже о том, что современный язык имеет огромный словарный запас, и работа по составлению такого словаря может быть выполнена только вручную, живой язык постоянно обновляется и словарь придется систематически пополнять. В то же время создание правил транскрибирования тоже не панацея, поскольку нельзя предугадать все ситуации, слова-исключения, аббревиатуры, да и грамматические ошибки, наконец. Поэтому на практике получила развитие комбинация обоих методов — то есть и создают правила произношения, и составляют словарь исключений. Кроме того, перед транскрибированием текст анализируется — проверяется грамматика, расшифровываются сокращения и аббревиатуры и т. д. Производится даже морфологический анализ — для синтезирования правильной интонации в предложениях (например, вопросительной или восклицательной).
Первую полнофункциональную TTS-систему для английского языка разработал Норико Умеда (Noriko Umeda) в Японии в 1968 году. Она обеспечивала вполне разборчивую речь, но была еще сильно далека по качеству от современных систем. В 1979 году появилась коммерческая TTS-система MITalk, разработанная в стенах Массачусетского Технологического Института (Massachusetts Institute of Technology) и изначально позиционировавшаяся как читающая машина для слепых. А двумя годами позже увидела свет еще одн



Хорошо! Пусть бы дальше пошли разработчики.Но ещё лучше было бы «выпевать» (клавиатурными-мидиклавиатура или гриф)на синтезаторе в виде музрифов(пассажей с различными штрихами,динамикой) отдельные строфы или стихотворения.
к сожалению не упомянули в истории наш страшный и могучий АНС,а так историческая подборка на 5
Забавный софт для распространения дурновкусицы. Безусловно, ещё рано человеку подделывать человека. Но обязательно нужно заниматься этим!